- ASP.NET Core Boilerplate
-
Security
-
Search Engine Optimization (SEO)
- Internet Favicon Madness (Updated)
- Building RSS/Atom Feeds for ASP.NET MVC
The aim of this post is to give your site better search engine rankings using special Search Engine Optimization (SEO) techniques. Take a look at the URL's below and see if you can spot the differences between them:
- http://example.com/one/two/
- https://example.com/one/two/
- http://example.com/one/two
- http://example.com/One/Two
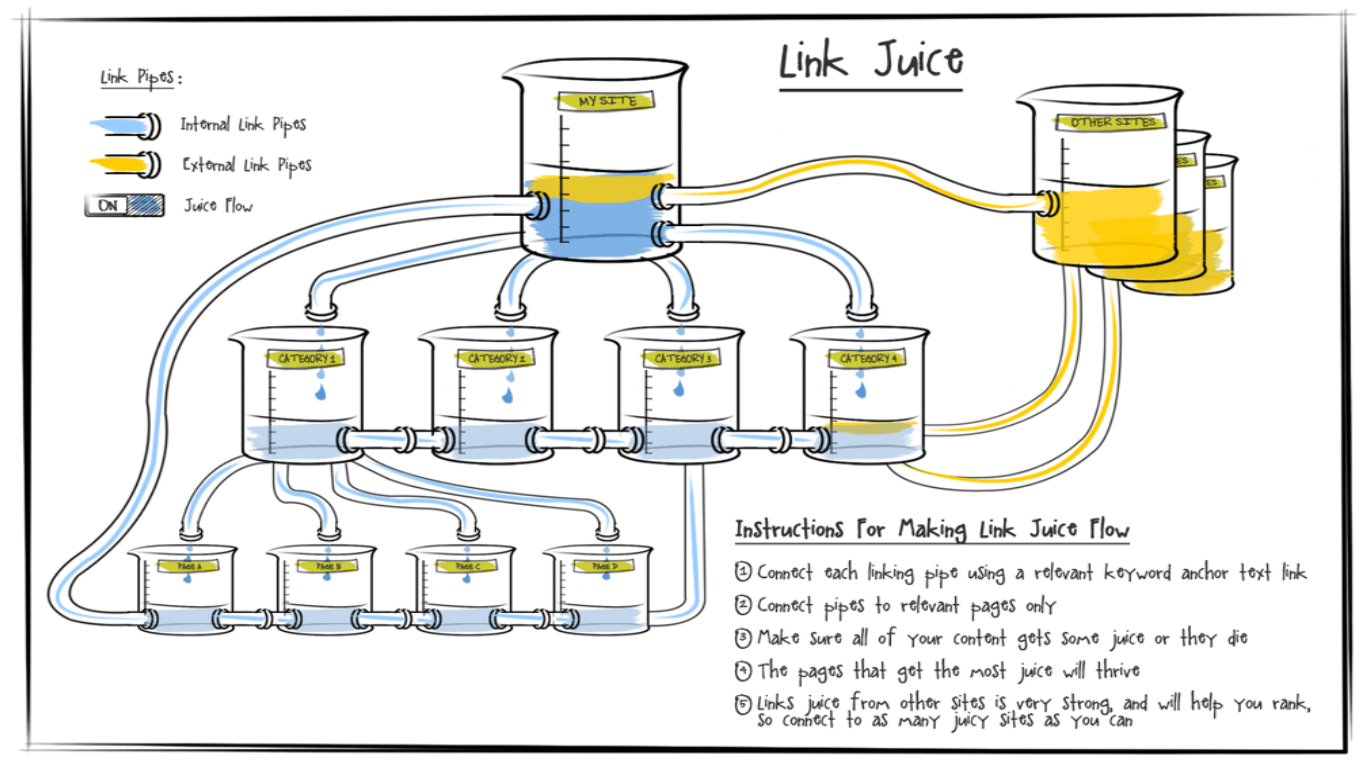
The second one has a HTTPS scheme, the third omits the trailing slash and the fourth has mixed case characters. All of the URL's point to the same resource but it turns out that search engines treat every one of these URL's as unique and different. Search engines give each URL a page rank, which determines where the resource will show up in the search results. Another term you will also hear quite often is 'link juice'. The link juice conceptualizes how page rank flows between pages and websites.
If your site exposes the above four different URL's to the single resource, your link juice is being spread against each one and as a result, that will be having a detrimental impact on your page rank.
The Canonical Link Tag
One way to solve this problem is to add a canonical link tag to the head of your HTML page. This tells search engines what the canonical (actual) URL to the page is. The link tag contains a URL to your preferred URL for the page.
One thing you must decide early on is your preferred URL for every page. You must ask yourself the following questions and use the resulting URL in your canonical link tag.
- Do I prefer this page to be HTTP or HTTPS? This is yet another reason to go with HTTPS across your entire site.
- Should the URL end with a trailing slash? This is often preferred over omitting it but it's a matter of preference.
- Should I allow a mix of upper-case and lower-case characters? Most sites choose to go with all lower-case characters.
When search engines follow a link to your page, regardless of which URL they followed to get to your page, all of the link juice will be given to the URL specified in your canonical link tag. Google goes into a lot more depth about this tag here.
301 Permanent Redirects
Unfortunately, using the canonical link tag is not the recommended approach. The intention is that it should only be used to retrofit older websites, so they can become optimized for search engines.
According to both Google and Bing, the recommended approach if you visit a non-preferred format of your pages URL is to perform a 301 permanent redirect to the preferred canonical URL. According to them, you only lose a tiny amount of link juice by doing a 301 permanent redirect.
Canonical URL's in MVC
ASP.NET MVC 5 and ASP.NET Core have two settings you can use to automatically create canonical URL's every time you generate URL's.
// Append a trailing slash to all URL's.
RouteTable.Routes.AppendTrailingSlash = true;
// Ensure that all URL's are lower-case.
RouteTable.Routes.LowercaseUrls = true;services.ConfigureRouting(
routeOptions =>
{
// Append a trailing slash to all URL's.
routeOptions.AppendTrailingSlash = true;
// Ensure that all URL's are lower-case.
routeOptions.LowercaseUrls = true;
});Once you apply these settings and are using the UrlHelper to generate all your URL's, you will see that across your site all URL's are lower-case and all end with a trailing slash (This is just my personal preference you may not like trailing slashes).
This means that within your site, no 301 permanent redirects to canonical URL's are required because the URL's are already canonical. However, this just solves part of the problem. What about external links to your site? What happens when people copy and paste your site and delete or add a trailing slash? What happens when someone types in a link to your site and puts in an upper-case character? The fact is you have no control over external links and when search engine crawlers follow those non-canonical links you will be losing valuable link juice.
301 Permanent Redirects in MVC
Enter the RedirectToCanonicalUrlAttribute. This is an MVC filter you can apply, which will check that the URL from each request is canonical. If it is, it does nothing and MVC returns the view in its response as normal. If the URL is not canonical, it generates the canonical URL based on the above MVC settings and returns a 301 permanent redirect response to the client. The client can then make another request to the correct canonical URL.
You can take a look at the source code for the RedirectToCanonicalUrlAttribute, NoTrailingSlashAttribute and NoLowercaseQueryStringAttribute's (I shall explain in a minute) for MVC 5 below or the ASP.NET Core version here.
/// <summary>
/// To improve Search Engine Optimization SEO, there should only be a single URL for each resource. Case
/// differences and/or URL's with/without trailing slashes are treated as different URL's by search engines. This
/// filter redirects all non-canonical URL's based on the settings specified to their canonical equivalent.
/// Note: Non-canonical URL's are not generated by this site template, it is usually external sites which are
/// linking to your site but have changed the URL case or added/removed trailing slashes.
/// (See Google's comments at http://googlewebmastercentral.blogspot.co.uk/2010/04/to-slash-or-not-to-slash.html
/// and Bing's at http://blogs.bing.com/webmaster/2012/01/26/moving-content-think-301-not-relcanonical).
/// </summary>
[AttributeUsage(AttributeTargets.Method | AttributeTargets.Class, Inherited = true, AllowMultiple = false)]
public class RedirectToCanonicalUrlAttribute : FilterAttribute, IAuthorizationFilter
{
private const char QueryCharacter = '?';
private const char SlashCharacter = '/';
private readonly bool appendTrailingSlash;
private readonly bool lowercaseUrls;
/// <summary>
/// Initializes a new instance of the <see cref="RedirectToCanonicalUrlAttribute" /> class.
/// </summary>
/// <param name="appendTrailingSlash">If set to <c>true</c> append trailing slashes, otherwise strip trailing
/// slashes.</param>
/// <param name="lowercaseUrls">If set to <c>true</c> lower-case all URL's.</param>
public RedirectToCanonicalUrlAttribute(
bool appendTrailingSlash,
bool lowercaseUrls)
{
this.appendTrailingSlash = appendTrailingSlash;
this.lowercaseUrls = lowercaseUrls;
}
/// <summary>
/// Gets a value indicating whether to append trailing slashes.
/// </summary>
/// <value>
/// <c>true</c> if appending trailing slashes; otherwise, strip trailing slashes.
/// </value>
public bool AppendTrailingSlash
{
get { return this.appendTrailingSlash; }
}
/// <summary>
/// Gets a value indicating whether to lower-case all URL's.
/// </summary>
/// <value>
/// <c>true</c> if lower-casing URL's; otherwise, <c>false</c>.
/// </value>
public bool LowercaseUrls
{
get { return this.lowercaseUrls; }
}
/// <summary>
/// Determines whether the HTTP request contains a non-canonical URL using <see cref="TryGetCanonicalUrl"/>,
/// if it doesn't calls the <see cref="HandleNonCanonicalRequest"/> method.
/// </summary>
/// <param name="filterContext">An object that encapsulates information that is required in order to use the
/// <see cref="RedirectToCanonicalUrlAttribute"/> attribute.</param>
/// <exception cref="ArgumentNullException">The <paramref name="filterContext"/> parameter is <c>null</c>.</exception>
public virtual void OnAuthorization(AuthorizationContext filterContext)
{
if (filterContext == null)
{
throw new ArgumentNullException(nameof(filterContext));
}
if (string.Equals(filterContext.HttpContext.Request.HttpMethod, "GET", StringComparison.Ordinal))
{
string canonicalUrl;
if (!this.TryGetCanonicalUrl(filterContext, out canonicalUrl))
{
this.HandleNonCanonicalRequest(filterContext, canonicalUrl);
}
}
}
/// <summary>
/// Determines whether the specified URl is canonical and if it is not, outputs the canonical URL.
/// </summary>
/// <param name="filterContext">An object that encapsulates information that is required in order to use the
/// <see cref="RedirectToCanonicalUrlAttribute" /> attribute.</param>
/// <param name="canonicalUrl">The canonical URL.</param>
/// <returns><c>true</c> if the URL is canonical, otherwise <c>false</c>.</returns>
protected virtual bool TryGetCanonicalUrl(AuthorizationContext filterContext, out string canonicalUrl)
{
bool isCanonical = true;
Uri url = filterContext.HttpContext.Request.Url;
canonicalUrl = url.ToString();
int queryIndex = canonicalUrl.IndexOf(QueryCharacter);
// If we are not dealing with the home page. Note, the home page is a special case and it doesn't matter
// if there is a trailing slash or not. Both will be treated as the same by search engines.
if (url.AbsolutePath.Length > 1)
{
if (queryIndex == -1)
{
bool hasTrailingSlash = canonicalUrl[canonicalUrl.Length - 1] == SlashCharacter;
if (this.appendTrailingSlash)
{
// Append a trailing slash to the end of the URL.
if (!hasTrailingSlash && !this.HasNoTrailingSlashAttribute(filterContext))
{
canonicalUrl += SlashCharacter;
isCanonical = false;
}
}
else
{
// Trim a trailing slash from the end of the URL.
if (hasTrailingSlash)
{
canonicalUrl = canonicalUrl.TrimEnd(SlashCharacter);
isCanonical = false;
}
}
}
else
{
bool hasTrailingSlash = canonicalUrl[queryIndex - 1] == SlashCharacter;
if (this.appendTrailingSlash)
{
// Append a trailing slash to the end of the URL but before the query string.
if (!hasTrailingSlash && !this.HasNoTrailingSlashAttribute(filterContext))
{
canonicalUrl = canonicalUrl.Insert(queryIndex, SlashCharacter.ToString());
isCanonical = false;
}
}
else
{
// Trim a trailing slash to the end of the URL but before the query string.
if (hasTrailingSlash)
{
canonicalUrl = canonicalUrl.Remove(queryIndex - 1, 1);
isCanonical = false;
}
}
}
}
if (this.lowercaseUrls)
{
foreach (char character in canonicalUrl)
{
if (this.HasNoLowercaseQueryStringAttribute(filterContext) && queryIndex != -1)
{
if (character == QueryCharacter)
{
break;
}
if (char.IsUpper(character) && !this.HasNoTrailingSlashAttribute(filterContext))
{
canonicalUrl = canonicalUrl.Substring(0, queryIndex).ToLower() +
canonicalUrl.Substring(queryIndex, canonicalUrl.Length - queryIndex);
isCanonical = false;
break;
}
}
else
{
if (char.IsUpper(character) && !this.HasNoTrailingSlashAttribute(filterContext))
{
canonicalUrl = canonicalUrl.ToLower();
isCanonical = false;
break;
}
}
}
}
return isCanonical;
}
/// <summary>
/// Handles HTTP requests for URL's that are not canonical. Performs a 301 Permanent Redirect to the canonical URL.
/// </summary>
/// <param name="filterContext">An object that encapsulates information that is required in order to use the
/// <see cref="RedirectToCanonicalUrlAttribute" /> attribute.</param>
/// <param name="canonicalUrl">The canonical URL.</param>
protected virtual void HandleNonCanonicalRequest(AuthorizationContext filterContext, string canonicalUrl)
{
filterContext.Result = new RedirectResult(canonicalUrl, true);
}
/// <summary>
/// Determines whether the specified action or its controller has the <see cref="NoTrailingSlashAttribute"/>
/// attribute specified.
/// </summary>
/// <param name="filterContext">The filter context.</param>
/// <returns><c>true</c> if a <see cref="NoTrailingSlashAttribute"/> attribute is specified, otherwise
/// <c>false</c>.</returns>
protected virtual bool HasNoTrailingSlashAttribute(AuthorizationContext filterContext)
{
return filterContext.ActionDescriptor.IsDefined(typeof(NoTrailingSlashAttribute), false) ||
filterContext.ActionDescriptor.ControllerDescriptor.IsDefined(typeof(NoTrailingSlashAttribute), false);
}
/// <summary>
/// Determines whether the specified action or its controller has the <see cref="NoLowercaseQueryStringAttribute"/>
/// attribute specified.
/// </summary>
/// <param name="filterContext">The filter context.</param>
/// <returns><c>true</c> if a <see cref="NoLowercaseQueryStringAttribute"/> attribute is specified, otherwise
/// <c>false</c>.</returns>
protected virtual bool HasNoLowercaseQueryStringAttribute(AuthorizationContext filterContext)
{
return filterContext.ActionDescriptor.IsDefined(typeof(NoLowercaseQueryStringAttribute), false) ||
filterContext.ActionDescriptor.ControllerDescriptor.IsDefined(typeof(NoLowercaseQueryStringAttribute), false);
}
}
/// <summary>
/// Requires that a HTTP request does not contain a trailing slash. If it does, return a 404 Not Found. This is
/// useful if you are dynamically generating something which acts like it's a file on the web server.
/// E.g. /Robots.txt/ should not have a trailing slash and should be /Robots.txt. Note, that we also don't care if
/// it is upper-case or lower-case in this instance.
/// </summary>
[AttributeUsage(AttributeTargets.Method | AttributeTargets.Class, Inherited = true, AllowMultiple = false)]
public class NoTrailingSlashAttribute : FilterAttribute, IAuthorizationFilter
{
private const char QueryCharacter = '?';
private const char SlashCharacter = '/';
/// <summary>
/// Determines whether a request contains a trailing slash and, if it does, calls the
/// <see cref="HandleTrailingSlashRequest"/> method.
/// </summary>
/// <param name="filterContext">An object that encapsulates information that is required in order to use the
/// <see cref="RequireHttpsAttribute"/> attribute.</param>
/// <exception cref="ArgumentNullException">The <paramref name="filterContext"/> parameter is null.</exception>
public virtual void OnAuthorization(AuthorizationContext filterContext)
{
if (filterContext == null)
{
throw new ArgumentNullException(nameof(filterContext));
}
string canonicalUrl = filterContext.HttpContext.Request.Url.ToString();
int queryIndex = canonicalUrl.IndexOf(QueryCharacter);
if (queryIndex == -1)
{
if (canonicalUrl[canonicalUrl.Length - 1] == SlashCharacter)
{
this.HandleTrailingSlashRequest(filterContext);
}
}
else
{
if (canonicalUrl[queryIndex - 1] == SlashCharacter)
{
this.HandleTrailingSlashRequest(filterContext);
}
}
}
/// <summary>
/// Handles HTTP requests that have a trailing slash but are not meant to.
/// </summary>
/// <param name="filterContext">An object that encapsulates information that is required in order to use the
/// <see cref="RequireHttpsAttribute"/> attribute.</param>
protected virtual void HandleTrailingSlashRequest(AuthorizationContext filterContext)
{
filterContext.Result = new HttpNotFoundResult();
}
}
/// <summary>
/// Ensures that a HTTP request URL can contain query string parameters with both upper-case and lower-case
/// characters.
/// </summary>
[AttributeUsage(AttributeTargets.Method | AttributeTargets.Class, Inherited = true, AllowMultiple = false)]
public class NoLowercaseQueryStringAttribute : FilterAttribute
{
}Adding the RedirectToCanonicalUrlAttribute filter is easy. You can add it to the global filters collection so all requests will be handled by it like so:
GlobalFilters.Filters.Add(new RedirectToCanonicalUrlAttribute(
RouteTable.Routes.AppendTrailingSlash,
RouteTable.Routes.LowercaseUrls));That's it! It's as simple as that! Now there are two special cases, which is where the NoTrailingSlashAttribute and NoLowercaseQueryStringAttribute filters comes in.
Special Case 1
Say you want to have the following action method where visiting http://example.com/robots.txt returns a text result. We want the client to think it's just visiting a static robots.txt file but in reality we are dynamically generating it (One reason for doing this is that a robots.txt file must contain an absolute URL and you want to use the UrlHelper to just handle that, no matter what domain the site is running under).
[NoTrailingSlash]
[Route("robots.txt")]
public ContentResult RobotsText()
{
string content = this.robotsService.GetRobotsText();
return this.Content(content, ContentType.Text, Encoding.UTF8);
}Adding a trailing slash to robots.txt would just be weird. Also, the last thing you want to do when search engines try to visit http://example.com/robots.txt is 301 permanent redirect them to http://example.com/robots.txt/. So we add the NoTrailingSlashAttribute filter.
The RedirectToCanonicalUrlAttribute knows about the NoTrailingSlashAttribute filter and when it sees it and we make a request to the above action, it ignores the AppendTrailingSlash setting and it works just like requesting a static robots.txt file from the file system.
Special Case 2
Sometimes you want your query string parameters to be a mix of upper-case and lower-case. When you want to do this, simply add the NoLowercaseQueryStringAttribute attribute to the action method like so:
[NoLowercaseQueryString]
[Route("action")]
public void Action(string mixedCaseParameter)
{
// mixedCaseParameter can contain upper and lower case characters.
}If you are using the ASP.NET Identity NuGet package for authentication, then take note, you need to apply the NoLowercaseQueryStringAttribute to the AccountController.
Conclusions
Once again, you can find a working example of this and much more using the ASP.NET Core Boilerplate project template or view the source code directly on GitHub.
Comment
Initializing...